如若轉(zhuǎn)載,請注明出處:http://www.tdmrzx.cn/product/41.html
更新時間:2026-02-25 08:06:30
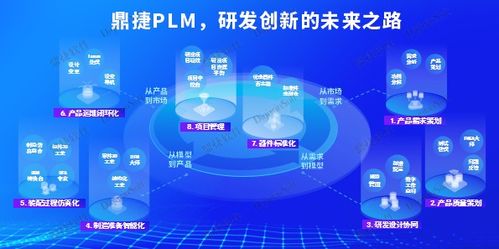
鼎捷受邀出席 中國制造業(yè)產(chǎn)品創(chuàng)新數(shù)字化國際峰會 ,共話工業(yè)軟件創(chuàng)新發(fā)展
家裝公司如何直播開發(fā)小區(qū)
圓明園將開啟元宇宙建設(shè) 攜手兩大集團(tuán),力圖重現(xiàn)圓明園盛景
photoshop制作軟件產(chǎn)品的綠色網(wǎng)頁布局
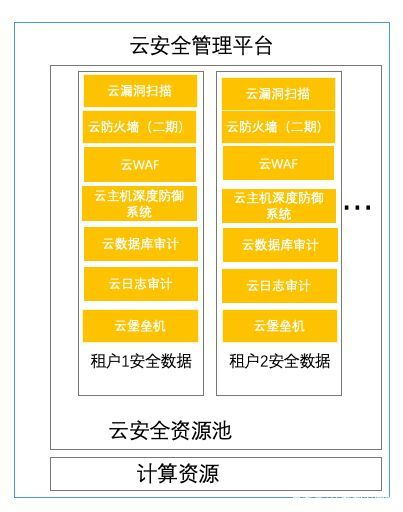
智安科普丨云安全到底是什么 云安全與傳統(tǒng)安全有什么區(qū)別
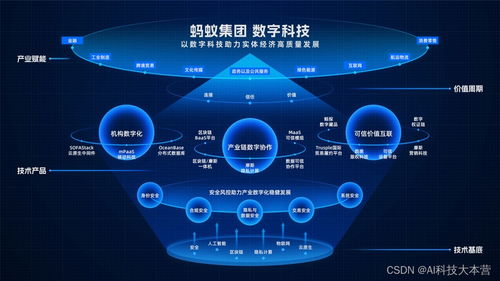
以數(shù)助實(shí)攻堅(jiān)產(chǎn)業(yè)協(xié)作 螞蟻集團(tuán)數(shù)字科技業(yè)務(wù)亮相云棲大會
奔跑吧it男saas軟件被it外包公司稱為派單神器
掏心窩文章 軟件外包公司的坑,你務(wù)必認(rèn)清楚這些
【軟件項(xiàng)目外包平臺公司|軟件項(xiàng)目外包平臺
地址:廣州市花都區(qū)南新華街五華村東華莊三街17號A108
Copyright © 2026 www.tdmrzx.cn 軟件外包 廣州塔圖姆網(wǎng)絡(luò)科技有限公司 版權(quán)所有 Sitemap